
Hypothesis tests 1
Statistical Hypothesis Testing Overview
Hypothesis testing is a procedure in inferential statistics. To draw reliable conclusions from a sample, you need to appreciate the differences between descriptive statistics and inferential statistics. Descriptive vs. Inferential Statistics Descriptive statistics summarize data for a group that you choose. This process allows you to understand that specific set of observations. Descriptive statistics describe a sample. That’s pretty straightforward. You simply take a group that you’re interested in, record data about the group members, and then use summary statistics and graphs to present the group properties. With descriptive statistics, there is no uncertainty because you are describing only the people or items that you actually measure. For instance, if you measure test scores in two classes, you know the precise means for both groups and can state with no uncertainty which one has a higher mean. You’re not trying to infer properties about a larger population.
However, if you want to draw inferences about a population, there are suddenly more issues you need to address. We’re now moving into inferential statistics. Drawing inferences about a population is particularly important in science where we want to apply the results to a larger population, not just the specific sample in the study.
For example, if we’re testing a new medication, we don’t want to know that it works only for the small, select experimental group. We want to infer that it will be effective for a larger population. We want to generalize the sample results to people outside the sample. Inferential statistics takes data from a sample and makes inferences about the larger population from which the sample was drawn. Consequently, we need to have confidence that our sample accurately reflects the population. This requirement affects our process. At a broad level, we must do the following:
- Define the population we are studying.
- Draw a representative sample from that population.
- Use analyses that incorporate the sampling error.
Intuition
Hypothesis testing is a form of inferential statistics that allows us to draw conclusions about an entire population based on a representative sample. You gain tremendous benefits by working with a sample. In most cases, it is simply impossible to observe the entire population to understand its properties. The only alternative is to collect a random sample and then use statistics to analyze it.
When your car breakdown you will make an educated guess that there may be not enough petrol or may be some technical problem. Then you will take car to the nearest workshop to validate your guess/assumption/hypothesis. Depend on Mechanic answer you will reject one hypothesis and accept another hypothesis.
Here Null hypothesis is “not enough petrol”; Alternate hypothesis is may be some technical problem.

While samples are much more practical and less expensive to work with, there are trade-offs. When you estimate the properties of a population from a sample, the sample statistics are unlikely to equal the actual population value exactly. For instance, your sample mean is unlikely to equal the population mean. The difference between the sample statistic and the population value is the sample error.
Why there is difference between sample and population?
Differences that researchers observe in samples might be due to sample error rather than representing a true effect at the population level. If sample error causes the observed difference, the next time someone performs the same experiment the results might be different. Hypothesis testing incorporates estimates of the sampling error to help you make the correct decision.
For example, if you are studying the proportion of defects produced by two manufacturing methods, any difference you observe between the two sample proportions might be sample error rather than a true difference. If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics. That can be a costly mistake!
Let’s cover some basic hypothesis testing terms that you need to know.
Effect
The effect is the difference between the population value and the null hypothesis value. The effect is also known as population effect or the difference. For example, the mean difference between the health outcome for a treatment group and a control group is the effect.
Typically, you do not know the size of the actual effect. However, you can use a hypothesis test to help you determine whether an effect exists and to estimate its size.
An effect can be statistically significant, but that doesn’t necessarily indicate that it is important in a real-world, practical sense.
Null Hypothesis
The null hypothesis is one of two mutually exclusive hypotheses in a hypothesis test. The null hypothesis states that a population parameter equals a specified value. If your sample contains sufficient evidence, you can reject the null hypothesis and conclude that the effect is statistically significant. The null hypothesis is often displayed as H0.
In every experiment, there is an effect or difference between groups that the researchers are testing. It could be the effectiveness of a new drug, building material, or other intervention that has benefits ,the durability of a new product, the proportion of defect in a manufacturing process, and so on.. Typically, the null hypothesis states that the true effect size equals zero that there is no difference between the groups. Therefore, if you can reject the null hypothesis, you can favor the alternative hypothesis, which states that the effect exists (doesn’t equal zero) at the population level.
A null hypothesis is a type of hypothesis used in statistics that proposes that there is no difference between certain characteristics of a population (or data-generating process).
Alternative hypothesis
The alternative hypothesis is one of two mutually exclusive hypotheses in a hypothesis test. The alternative hypothesis states that a population parameter does not equal a specified value. Typically, this value is the null hypothesis value associated with no effect, such as zero. If your sample contains sufficient evidence, you can reject the null hypothesis and favor the alternative hypothesis. The alternative hypothesis is often denoted as H1 or HA.
If you are performing a two-tailed hypothesis test, the alternative hypothesis states that the population parameter does not equal the null hypothesis value. For example, when the alternative hypothesis is HA: μ ≠ 0, the test can detect differences both greater than and less than the null value.
A one-tailed alternative hypothesis can test for a difference only in one direction. For example, HA: μ > 0 can only test for differences that are greater than zero.
After formulating your null and alternative hypothesis according to your experiment and data collected you have to watch out your words describing both
So in the null hypothesis we talked about what we can assume we talked about what the status quo is or an assumption or we talked about previous given data and we perform test on it to judge its validity. While in the alternative hypothesis we might have something that is unknown to us we’re making some assertion about the world that we really don’t know we’re making a claim about something that we really do not know so it’s about something that we’re unsure of we can not assume to be true or something along those lines so think of this as this might be true let’s test it if not the truth is something else so over here on the null side we’re saying whatever our null hypothesis is stating we’re saying that this is accepted as true let’s test it on the alternative hypothesis side we’re saying this might be true we’re not quite sure let’s test it and if not the truth is something else.
P-values
In statistics, the p-value is the probability of obtaining results as extreme as the observed results of a statistical hypothesis test, assuming that the null hypothesis is correct. The p-value is used as an alternative to rejection points to provide the smallest level of significance at which the null hypothesis would be rejected. A smaller p-value means that there is stronger evidence in favor of the alternative hypothesis.
There are many different types of statistical tests out there that can all produce p-values. And you need to know which one to use since different situations could call for different statistical tests. Many of them are not interchangeable, and there is no almighty test that can cover all scenarios.
Significance Level (Alpha)
The significance level, also known as alpha or α. It specifies how strongly the sample evidence must contradict the null hypothesis before you can reject the null for the entire population. This standard is defined by the probability of rejecting a null hypothesis that is true. In other words, it is the probability that you say there is an effect when there is no effect. Lower significance levels indicate that you require stronger evidence before you will reject the null.
For instance, a significance level of 0.05 signifies a 5% risk of deciding that an effect exists when it does not exist.
A common misconception is that statistical hypothesis tests are designed to select the more likely of two hypotheses. Instead, a test will remain with the null hypothesis until there is enough evidence (data) to support the alternative hypothesis.
Examples of questions you can answer with a hypothesis test:
- Does the mean height of undergraduate women differ from 66 inches?
- Is the standard deviation of their height equal less than 5 inches?
- Do male and female undergraduates differ in height?

There are mainly three formula for hypothesis testing formula which are:
1 — H0 = & Ha !=
2- H0 ≤ & Ha >
3- H0 ≥ & Ha<
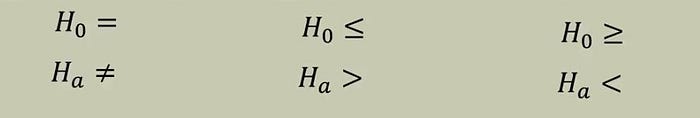
After choosing our formula this determine if we will do a one tailed or two tailed Hypothesis test.
Choosing whether to perform a one-tailed or a two-tailed hypothesis test is one of the methodology decisions you might need to make for your statistical analysis. This choice can have critical implications for the types of effects it can detect, the statistical power of the test, and potential errors.
In this article, you’ll learn about the differences between one-tailed and two-tailed hypothesis tests and their advantages and disadvantages. I include examples of both types of statistical tests.
First, we need to cover some background material to understand the tails in a test. Typically, hypothesis tests take all of the sample data and convert it to a single value, which is known as a test statistic.
These test statistics follow a sampling distribution. Probability distribution plots display the probabilities of obtaining test statistic values when the null hypothesis is correct. On a probability distribution plot, the portion of the shaded area under the curve represents the probability that a value will fall within that range.
The graph below displays a sampling distribution for t-values. The two shaded regions cover the two-tails of the distribution.
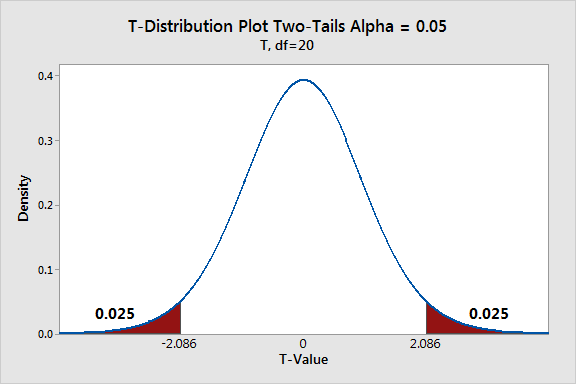
Critical Regions in a Hypothesis Test
In hypothesis tests, critical regions are ranges of the distributions where the values represent statistically significant results. Analysts define the size and location of the critical regions by specifying both the significance level (alpha) and whether the test is one-tailed or two-tailed.
Consider the following two facts:
1- The significance level is the probability of rejecting a null hypothesis that is correct.
2- The sampling distribution for a test statistic assumes that the null hypothesis is correct.
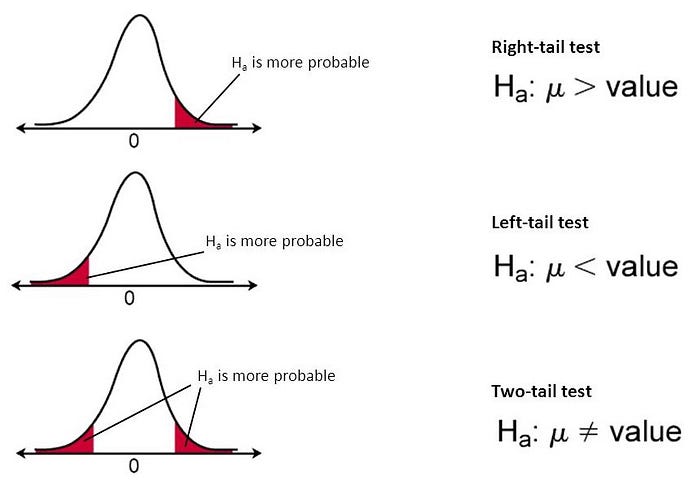
Two-Tailed Hypothesis Tests
Two-tailed hypothesis tests are also known as non-directional and two-sided tests because you can test for effects in both directions. When you perform a two-tailed test, you split the significance level percentage between both tails of the distribution.
In a two-tailed test, the generic null and alternative hypotheses are the following:
- Null: The effect equals zero.
- Alternative: The effect does not equal zero.
Advantages of two-tailed hypothesis tests
You can detect both positive and negative effects. Two-tailed tests are standard in scientific research where discovering any type of effect is usually of interest to researchers.
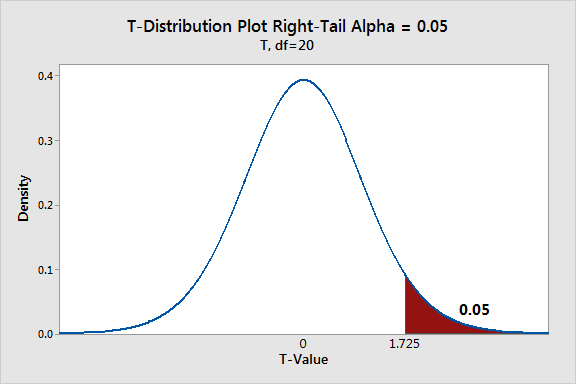
One-Tailed Hypothesis Tests
One-tailed hypothesis tests are also known as directional and one-sided tests because you can test for effects in only one direction. When you perform a one-tailed test, the entire significance level percentage goes into the extreme end of one tail of the distribution.
In a one-tailed test, you have two options for the null and alternative hypotheses, which corresponds to where you place the critical region.
You can choose either of the following sets of generic hypotheses:
- Null: The effect is less than or equal to zero.
- Alternative: The effect is greater than zero.
Or:
- Null: The effect is greater than or equal to zero.
- Alternative: The effect is less than zero.
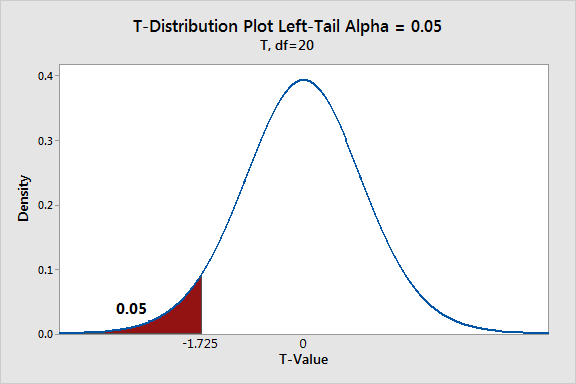
Again, the specifics of the hypotheses depend on the type of test you perform.
Advantages and disadvantages of one-tailed hypothesis tests
One-tailed tests have more statistical power to detect an effect in one direction than a two-tailed test with the same design and significance level. One-tailed tests occur most frequently for studies where one of the following is true:
- Effects can exist in only one direction.
- Effects can exist in both directions but the researchers only care about an effect in one direction. There is no drawback to failing to detect an effect in the other direction. (Not recommended.)
The disadvantage of one-tailed tests is that they have no statistical power to detect an effect in the other direction.
TO SUM UP
